











模型

VAE
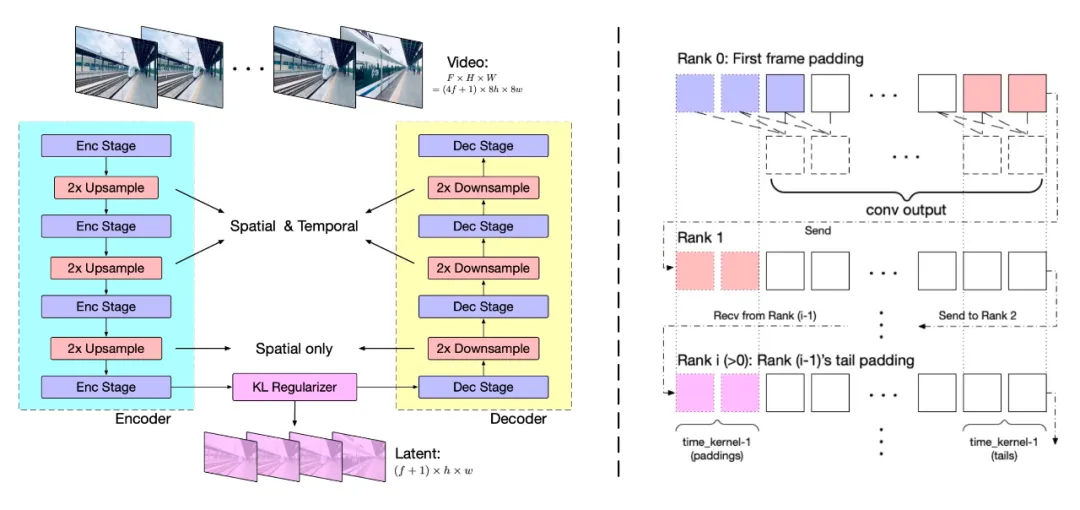
专家 Transformer
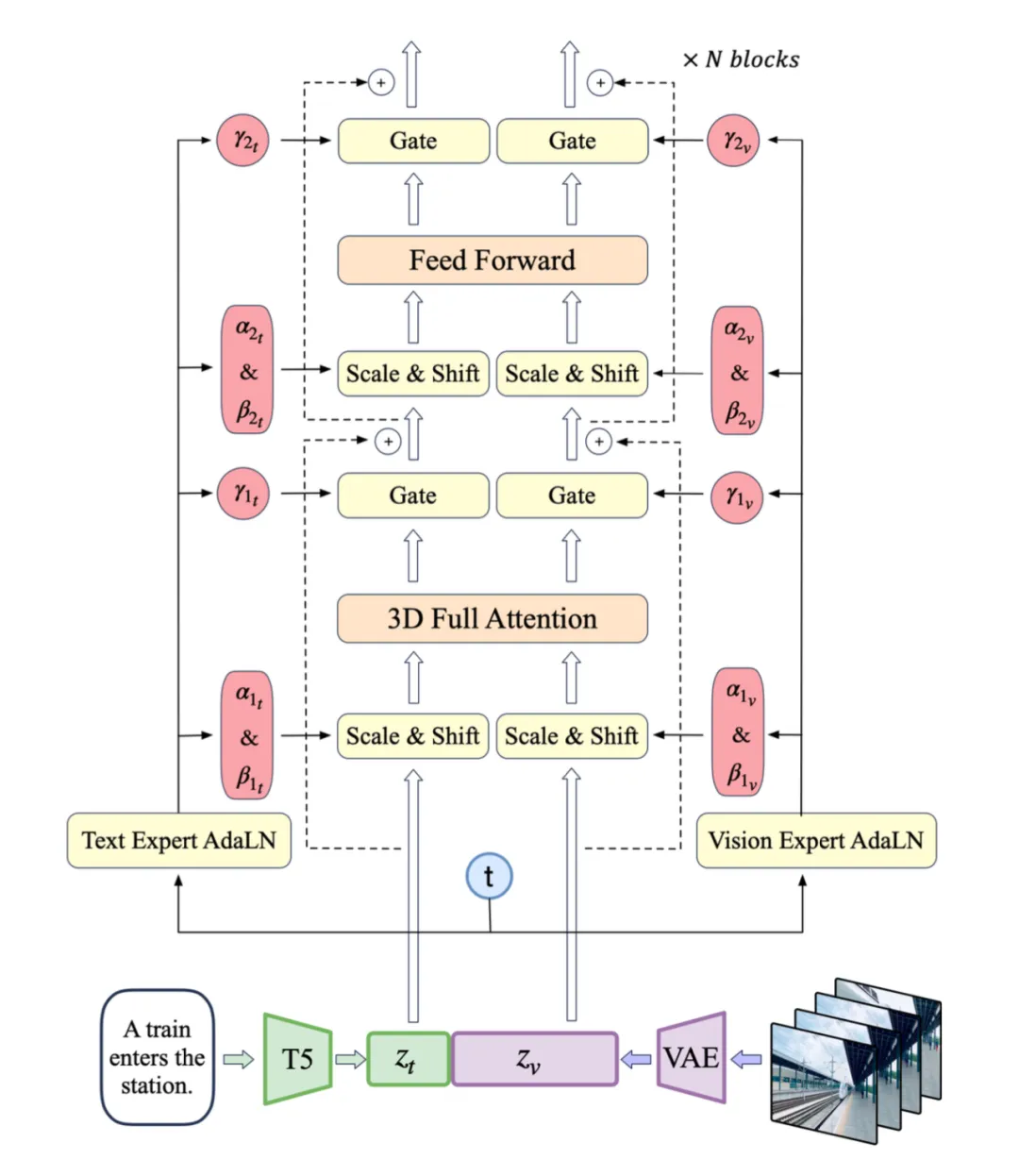
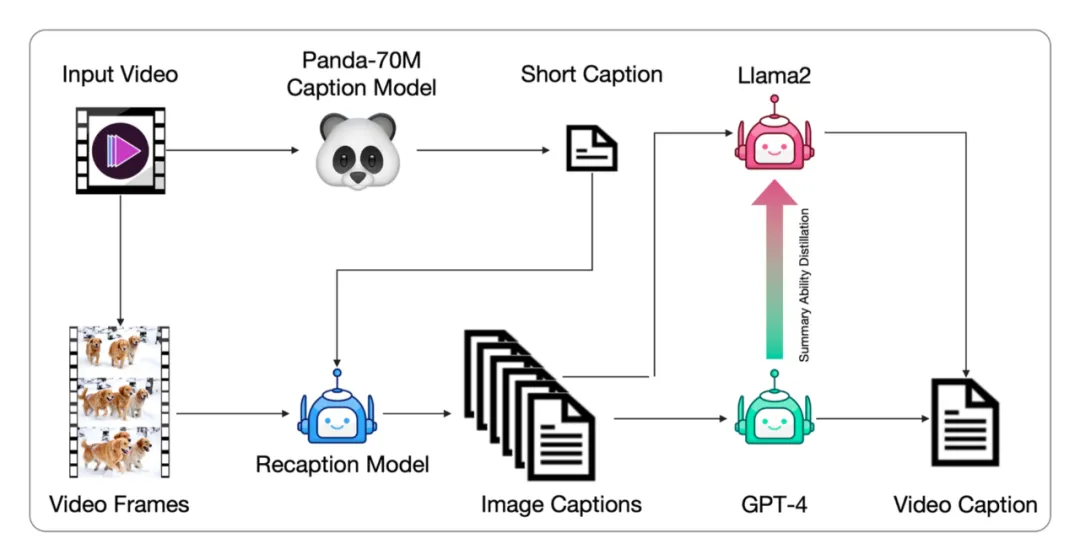
Data
性能
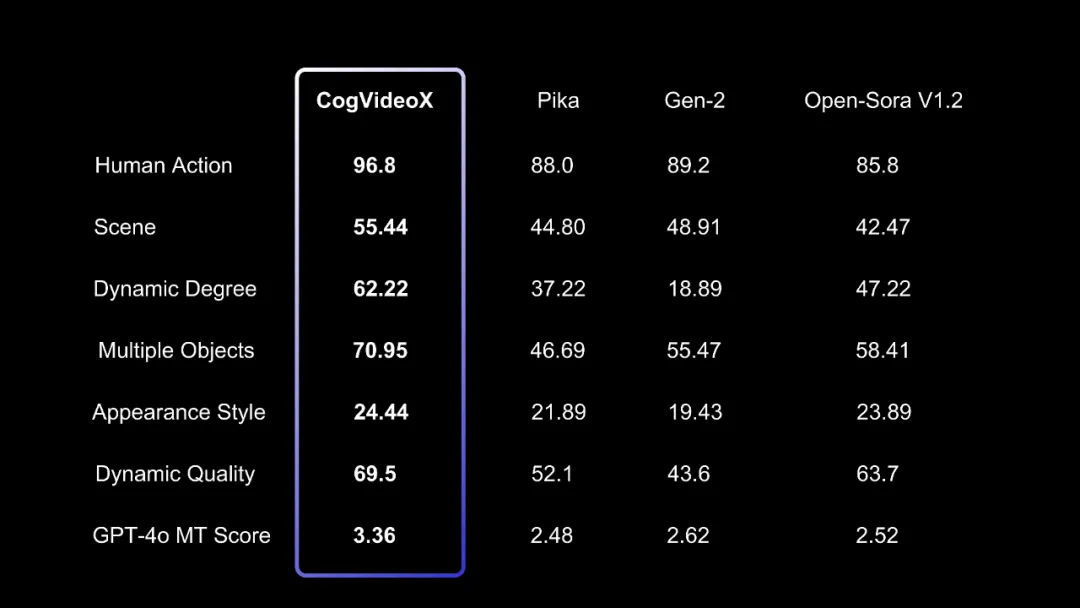
我们已经验证了scaling law在视频生成方面的有效性,未来会在不断 scale up 数据规模和模型规模的同时,探究更具突破式创新的新型模型架构、更高效地压缩视频信息、更充分地融合文本和视频内容。
Demo
In the haunting backdrop of a war-torn city, where ruins and crumbled walls tell a story of devastation, a poignant close-up frames a young girl. Her face is smudged with ash, a silent testament to the chaos around her. Her eyes glistening with a mix of sorrow and resilience, capturing the raw emotion of a world that has lost its innocence to the ravages of conflict.
